 Updates from Arif RSS
Updates from Arif RSS
-
09:34:55 pm on August 24, 2010 |
Geman S, Bienenstock E, Doursat R. 1992. Neural networks and the bias/variance dilemma. Neural Comput 4:1-58.
-
03:07:29 pm on August 24, 2010 |
Bias-variance dilemma (Geman et al., 1992). It can be demonstrated that the mean square value of the estimation error between the function to be modelled and the neural network consists of the sum of the (squared) bias and variance. With a neural network using a training set of fixed size, a small bias can only be achieved with a large variance (Haykin, 1994). This dilemma can be circumvented if the training set is made very large, but if the total amount of data is limited, this may not be possible.
-
12:02:26 pm on August 24, 2010 |
Rajkumar T, Bardina J. 2003. Training data requirement for a neural network to predict aerodynamic coefficients. Di dalam: Bell AJ, Wickerhauser MV, Szu HH. Proceedings of Independent Component Analyses, Wavelets, and Neural Networks; Orlando: 22 Apr 2003. Orlando: SPIE. hlm (5102):92-103.
-
05:41:53 am on August 24, 2010 |
Perhaps the greatest problem that is faced in most attempts to use artificial neural networks for ecological applications is that the quantity of data is often very limited. Although there are a few cases where large amounts of data are available, as in the case of remote sensing or observations based on automatic telemetry, it is far more common to have to deal with limited and irregularly spaced data, and the data may not always be strictly comparable due to variations in environmental conditions between sampling periods. In most situation the collection of field data is both time-consuming and expensive.
Since the training and testing of neural networks is very data-intensive, this poses serious obstacles to the development of neural network applications in ecology.
-
05:36:07 am on August 24, 2010 |
Silvert W, Baptist M. 1998. Can neuronal networks be used in data-poor situations? Di dalam: Lek S, Guégan JF. Artificial Neuronal Networks: Application to Ecology and Evolution. Berlin: Springer-Verlag. hlm 241-248.
-
01:03:43 pm on August 22, 2010 |
Chan LW. 1996. Levenberg-Marquardt learning and regularization. Progress Neural Inform Processing 139-144.
-
12:41:37 pm on August 22, 2010 |
Stone 1974 is referenced in:
Michaelsen J. 1987. Cross-validation in statistical climate forecast models. J Climate Applied Meteorology, 26:1589-16001520-0450(1987)026-1589-cviscf-2.0.co;2.pdfSet
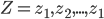 consists of predictions and targets
consists of predictions and targets 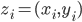
A set of prediction rule
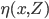 will be used to predict y0 from
will be used to predict y0 from 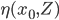
Let
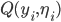 be the accuracy.
be the accuracy.
by least squares this will usually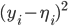
in other words expected Err is
![Err= E[Q(y_{i},\eta(x_{0},Z))]](http://lakm.us/thesit/wp-content/uploads/eq_a3a3253210769351b42ecc2c29b07f59.png)
MSE
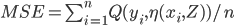
In cross validation
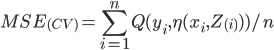
-
12:19:08 pm on August 22, 2010 |
If we assume a normally distributed population with mean μ and standard deviation σ, and take sample
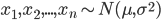
statistical error is then
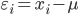
Residual
while residual is
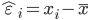
hat over the letter ε indicates an observable estimate of an unobservable quantity called ε.
-
07:29:29 am on August 22, 2010 |
Drawing boxplot from the following data, whiskers are determined from 1.5 IQR
no datum drawn as 1 0.026 outlier 2 0.048 whisker low 3 0.070 Q1 4 0.072 5 0.076 Q2 6 0.084 7 0.086 8 0.099 Q3 9 0.102 10 0.103 whisker high Outlier
0.026 becomes outlier because 1.5IQR boundary (IQR = Q3 – Q1 = 0.02908) for the lower boundary is Q1 -1.5IQR = 0.0404, hence whisker is 0.048 which is more close to the box inside making 0.026 outlier.

boxplot-basic-concept-example.png
-
06:43:00 am on August 22, 2010 |
Viscosity is a measure of the resistance of a fluid which is being deformed by either shear stress or tensile stress.
The cgs physical unit for dynamic viscosity is the poise (P), more commonly expressed, particularly in ASTM standards, as centipoise (cP)